

DocForge
Abstract
Abstract
Github repository: https://github.com/Shriyabh11/DocForge
Google meet link:https://meet.google.com/qxg-jphp-hnb
Aim
To build, fine-tune, and evaluate a transformer-based model that automatically generates complete function-level documentation from source code, including descriptions, parameter explanations, and return values.
Introduction
Software documentation is essential for maintainable and understandable code, yet developers often neglect writing detailed documentation due to time constraints and project complexity.
DocForge addresses this problem by automatically generating high-quality documentation directly from source code using deep learning and natural language processing techniques. The project fine-tunes CodeT5, a transformer model specialized for code understanding and generation, on the Code2Doc dataset containing curated function-documentation pairs across multiple programming languages.
The system analyzes code structure and semantics to produce human-readable descriptions, parameter explanations, and return value summaries. The final model is integrated into a Streamlit web application for real-time documentation generation.
Literature Survey and Technologies Used
Literature Survey
- Code2Doc (2025) introduced a high-quality curated dataset for automatic code documentation generation using strict filtering and quality scoring techniques.
- CodeT5 (2021) proposed an encoder-decoder transformer architecture specifically designed for programming language understanding and code generation tasks.
- Attention Is All You Need (2017) introduced the transformer architecture and attention mechanisms that form the foundation of modern large language models.
- BLEU and ROUGE-L metrics are widely used evaluation techniques for measuring text generation quality and similarity between generated and reference outputs.
Technologies Used
- Python
- PyTorch
- Hugging Face Transformers
- CodeT5-base
- Streamlit
- Kaggle GPU (NVIDIA T4)
- BLEU and ROUGE-L evaluation metrics
Methodology
Dataset
The Code2Doc dataset containing 13,358 curated code-documentation pairs was used. The dataset includes Python, Java, TypeScript, JavaScript, and C++ functions.
The dataset undergoes:
- Basic filtering
- Quality scoring
- Deduplication
- AI-content detection
Dataset Statistics
The Code2Doc dataset used for training contains 13,358 curated code-documentation pairs after a four-stage filtering process. It includes five programming languages: Python, Java, TypeScript, JavaScript, and C++. Java formed the largest portion of the dataset with 61.4% samples, while Python contributed 27%. The dataset achieved a mean quality score of 6.93/10, ensuring reliable training data.
Four-Stage Curation Pipeline
Stage 1 — Basic Filtering: removes trivial docs, test functions, placeholders
Stage 2 — Quality Scoring: 8-dimension weighted score, threshold ≥ 6.0
Stage 3 — Deduplication: exact hash + MinHash-LSH near-duplicate removal
Stage 4 — AI Content Detection: heuristic flagging of LLM-generated docs
Model & Architecture
CodeT5 — Seq2Seq Fine-Tuning
CodeT5 is an encoder-decoder transformer pre-trained on large-scale code corpora (GitHub, CodeSearchNet). It is purpose-built for code understanding and generation, making it ideally suited for the code → docstring task.
Input Format
Input: "Summarize {language}: {function_code}"
Target: "{documentation}"
How It Works
- The encoder reads the full source code using bidirectional multi-head self-attention
- Each token attends to all other tokens — capturing long-range code structure
- The decoder generates the docstring token by token
- Cross-attention allows the decoder to focus on relevant parts of the encoded source
- Output ends when the model produces the end-of-sequence token
CodeT5-base was selected for this project because it is specifically designed for code understanding and generation tasks using an encoder-decoder architecture, making it more suitable for generating structured documentation than general-purpose models like Llama 3.1 8B. The model, containing 222M parameters, was fine-tuned on the Code2Doc dataset with 9,192 training, 1,022 validation, and 1,293 test samples, using an input length of 512 tokens and output length of 256 tokens. Training was performed on NVIDIA T4 GPUs through Kaggle with an effective batch size of 16 using gradient accumulation. The model showed consistent improvement during training, with decreasing loss values and increasing validation BLEU scores, reaching 0.512 in the final epoch, indicating improved documentation generation performance.
Evaluation
The generated documentation was evaluated using:
- BLEU Score
- ROUGE-L Score
Deployment
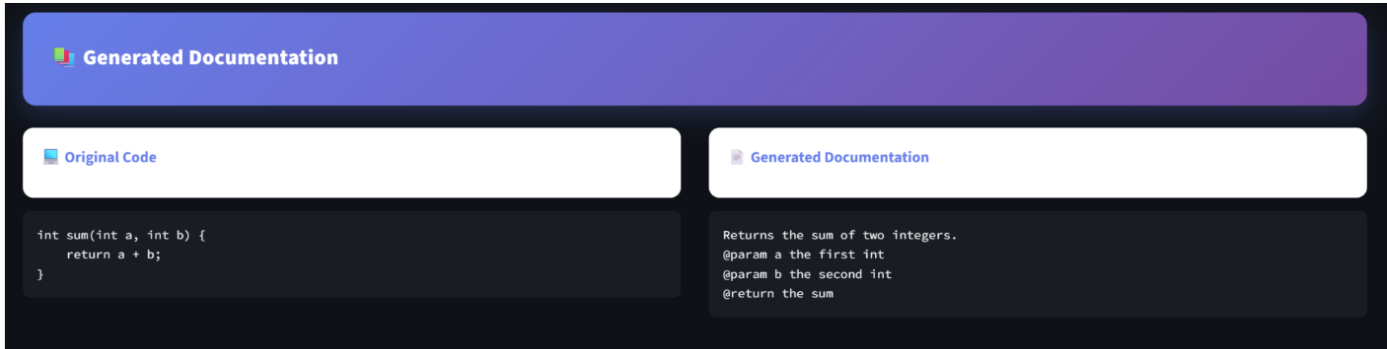
The final trained model was integrated into a Streamlit web application for interactive documentation generation.
Dashboard

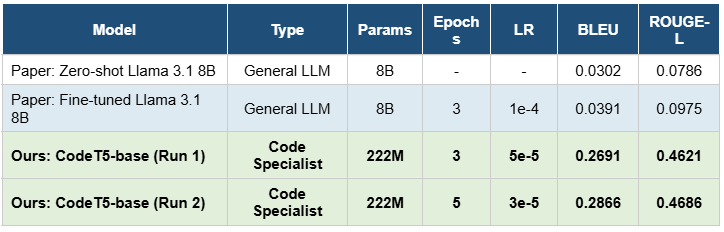
Results
Key Findings
- CodeT5 significantly outperformed the fine-tuned Llama 3.1 8B baseline despite being much smaller.
- Hyperparameter tuning improved both BLEU and ROUGE-L performance.
- High-quality curated datasets proved more effective than larger noisy datasets.
Conclusions
DocForge demonstrates that domain-specific transformer models can effectively generate accurate and useful code documentation. Fine-tuning CodeT5 on curated datasets produced strong performance and significantly outperformed larger general-purpose language models.
Future Scope
- Support additional programming languages
- Improve semantic accuracy
- Add repository-level documentation generation
- Include human feedback evaluation mechanisms
References
Karaman, R.K. & Akarsu, M. (2025). Code2Doc: A Quality-First Curated Dataset for Code Documentation.
Wang, Y. et al. (2021). CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation.
Vaswani, A. et al. (2017). Attention Is All You Need.
Papineni, K. et al. (2002). BLEU: A Method for Automatic Evaluation of Machine Translation.
Lin, C.Y. (2004). ROUGE: A Package for Automatic Evaluation of Summaries.
Mentors and Mentees Details
Mentors
- Shriya Bharadwaj
- Priyadharshni S
Mentees
- Dhruv Bhavesh Chokshi
- Harsh Raj
- Aadit Munje
- Shreevarna S Rao
- Dharsini Nakulan
Report Information
Team Members
Team Members
Report Details
Created: May 18, 2026, 5:52 p.m.
Approved by: None
Approval date: None
Report Details
Created: May 18, 2026, 5:52 p.m.
Approved by: None
Approval date: None