

TotoRoam
Abstract
Abstract
Join the meet: TotoRoam
Aim
The aim of this project is to implement the CycleGAN architecture from scratch and apply it to unpaired image translation. Rather than working with aligned domain pairs (as in Pix2Pix), CycleGAN learns the underlying relationship between two domains using only unpaired image collections. This makes it usable for tasks where paired data isn’t available, such as turning photographs into artwork, changing seasons, or object transfiguration.
The specific application here is photo-to-Ghibli-style translation: given a real photograph, the model learns to render it in the style of Studio Ghibli animated films.

Introduction
Image-to-image translation refers to converting images from one visual domain to another. For example, day-to-night, horse-to-zebra, or photo-to-painting. Supervised approaches like Pix2Pix (Isola et al., 2017) require aligned pairs of images, one from each domain, for every training example. This is a strong constraint: it means you need a photograph and its corresponding painting, a summer scene and the exact same winter scene, and so on.
CycleGAN by Zhu et al. (2020) solves this by training on unordered, unpaired collections. It learns two translation functions, G: X → Y (e.g., photo to painting) and F: Y → X (painting to photo) jointly. The key insight is the cycle consistency loss: if you translate a photo into a painting and then back again, you should recover the original photo. This structural constraint prevents the network from mapping all inputs to the same output (mode collapse) without needing paired supervision.
The model architecture consists of:
- Two generators (G and F), each a sequential encoder-decoder with a residual block bottleneck of 6 residual blocks.
- Two discriminators (D_X and D_Y), each a 70×70 PatchGAN that scores local patches rather than the full image.
- Three loss terms: adversarial loss, cycle consistency loss (L1), and optionally identity loss.
Literature Survey and Background
1. Generative Adversarial Networks (GANs)
Introduced by Goodfellow et al. (2014), GANs consist of a generator G and a discriminator D trained adversarially. G learns to produce outputs that fool D, while D learns to tell real from generated. The adversarial loss is:
L_GAN(G, D) = E[log D(y)] + E[log(1 − D(G(x)))]
2. Pix2Pix (Supervised Image Translation)
Isola et al. (2017) built on cGANs to learn paired image translation. The generator is a U-Net and the discriminator is a PatchGAN. The loss combines adversarial loss with an L1 pixel-level term (weighted by λ). Pix2Pix is the direct predecessor of CycleGAN; it requires paired data, which CycleGAN eliminates.
3. CycleGAN (Unpaired Image Translation)
Zhu et al. (2020) extend the GAN framework to the unpaired setting by training two generators and two discriminators simultaneously. The full loss is:
L(G, F, D_X, D_Y) = L_GAN(G, D_Y, X, Y) + L_GAN(F, D_X, Y, X) + λ · L_cyc(G, F)
where the cycle consistency loss is: L_cyc(G, F) = E[||F(G(x)) − x||_1] + E[||G(F(y)) − y||_1]. The paper sets λ = 10 for all experiments. An optional identity loss is also introduced for colour-preservation tasks.
4. Related Approaches
Several concurrent methods also tackle unpaired translation. CoGAN uses shared weights across two generators to learn a joint distribution. SimGAN uses an adversarial loss with an L1 pixel-regularisation term. BiGAN/ALI learns both a generator and its inverse. CycleGAN outperforms all of these on standard benchmarks.
Methodology
Problem Statement
Given two unpaired image collections, a source domain X (real photographs) and a target domain Y (Ghibli-style artwork), the goal is to learn G : X → Y and F : Y → X such that:
- Translated images are visually indistinguishable from the target distribution (adversarial objective).
- The mappings are consistent in both directions (cycle consistency).
- Optional: when a target-domain image is fed to the corresponding generator, it is returned unchanged (identity constraint).
Dataset
- Source domain (trainA): Real photographs.
- Target domain (trainB): Ghibli-style anime images.
Preprocessing: Images are loaded as RGB, resized to 286×286, randomly cropped to 256×256, and normalised to [−1, 1]. The random crop provides a form of data augmentation. Since this is unpaired training, the target image is selected randomly from its folder independently of the source index.
Model Architecture
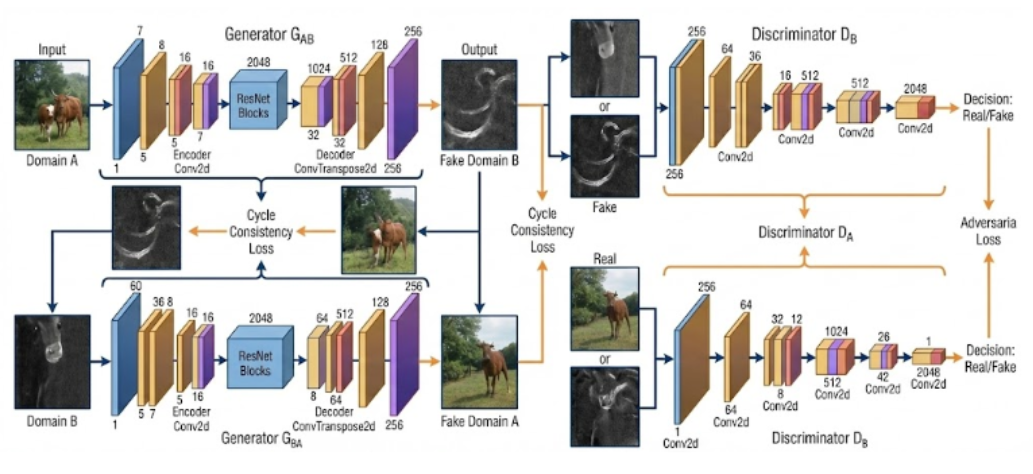
Building Blocks
- Conv_block: Conv2d → InstanceNorm2d → Activation. Uses LeakyReLU (slope 0.2) for the discriminator and GELU for the generator encoder. Stride 2 for downsampling.
- Upsample_block: ConvTranspose2d (stride 2) → InstanceNorm2d → Dropout(0.5) → GELU. Used in the generator decoder for upsampling.
- Res_Block: Two 3×3 convolutions with reflection padding and instance norm, plus a residual skip connection. Dropout(0.5) is applied after the first conv. Implements the residual block from Johnson et al. (2016).
Generator
The generator follows the ResNet-based design from Johnson et al. (2016), adapted for CycleGAN. It is a sequential encoder-decoder with a residual block bottleneck:
- Encoder: initial 7×7 convolution, followed by two strided convolutions that downsample from 256×256 to 64×64 while expanding channels from 3 to 256.
- Bottleneck: 6 residual blocks at 64×64. This is where domain-level feature transformation happens.
- Decoder: two transposed convolutions that upsample back to 256×256, followed by a final 7×7 convolution and Tanh to produce output in [−1, 1].
Discriminator
PatchGAN architecture: classifies 70×70 overlapping patches as real or fake.
- First layer: 4×4 convolution with stride 2, no normalisation.
- Three further convolutional layers progressively expanding channels up to 512.
- Final layer outputs a spatial map where each value scores one patch.
The patch-level design has fewer parameters than a full-image discriminator and enforces local realism.
Loss Functions
Adversarial Loss (Least-Squares GAN)
The original CycleGAN paper replaces binary cross-entropy with least-squares loss (LSGAN, Mao et al. 2017) for training stability:
- Generator loss: E[(D(G(x)) − 1)²] — pushes generated images toward the real label.
- Discriminator loss: E[(D(y) − 1)²] + E[(D(G(x)))²] — separates real and fake scores.
Label smoothing is applied: the discriminator targets 0.9 for real (instead of 1.0) and 0.0 for fake.
Cycle Consistency Loss
L_cyc = E[||F(G(x)) − x||₁] + E[||G(F(y)) − y||₁]
Both forward and backward cycle losses are summed and scaled by λ = 10.
Identity Loss
L_id = E[||G(y) − y||₁] + E[||F(x) − x||₁]
Scaled by λ × 0.5 = 5. When the input already belongs to the target domain, the output should not change. This is particularly useful for colour preservation.
Total Generator Loss
Sum of identity, cycle, and adversarial losses across both domains.
Total Discriminator Loss
Sum of real and fake losses across both domains, scaled by 0.5 to slow discriminator learning relative to the generators.
Training Procedure
Training Loop
Each iteration follows this sequence:
- Freeze discriminators, run both generators forward (translation + cycle reconstruction + identity).
- Compute and backpropagate total generator loss (adversarial + cycle + identity). Update generators.
- Unfreeze discriminators, update using experience replay buffer and label-smoothed losses.
Results




Metrics:
FCN Score:
- FCN Semantic Consistency: measures whether the generator preserves scene semantics by comparing FCN-ResNet50 segmentation maps of the source and generated images.
- Pixel Acc: 0.9674
- Mean Class Acc: 0.7842
- Mean IoU: 0.7353.
- High pixel accuracy confirms scene layout and object structure are preserved post-translation.
- FCN was trained on photorealistic data, lower scores on Ghibli outputs may reflect style transfer success rather than semantic failure.
Technical Challenges and Solutions
- Training instability: mitigated via LSGAN loss, experience replay, label smoothing, and linear LR decay.
- Mode collapse: cycle consistency loss counters this by requiring translations to be invertible.
- Colour drift: identity loss penalises unnecessary colour changes when input already belongs to the target domain.
- Geometric changes: CycleGAN handles texture/colour shifts well but struggles with spatial transformations.
- Memory: batch size 1, high-precision matmul enabled
- Unpaired sampling: target image index is randomised independently of source, correctly simulating unpaired training.
Conclusion
This project implements CycleGAN for unpaired photo-to-Ghibli-style image translation. The core contribution of the original paper, the cycle consistency loss, is correctly implemented alongside adversarial training, identity regularisation, experience replay, and a linear learning rate schedule. The architecture faithfully follows the ResNet generator and PatchGAN discriminator described by Zhu et al.
The implementation demonstrates that unpaired image translation is feasible with the right structural constraint. The cycle consistency loss acts as a self-supervised signal: the generator cannot simply discard input information, because the inverse generator must recover the original. This is what makes CycleGAN work without any paired data.
Future Scope
-
Increasing ResBlock_num to 9 (the paper's default for 256×256) may improve quality.
-
Perceptual loss (VGG feature matching) could improve visual quality for artistic style transfer.
- Conditional CycleGAN variants could allow more control over the output style.
References
[1] Zhu, J.-Y., Park, T., Isola, P., & Efros, A. A. (2020). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv:1703.10593v7.
[2] Isola, P., Zhu, J.-Y., Zhou, T., & Efros, A. A. (2017). Image-to-Image Translation with Conditional Adversarial Networks. CVPR 2017.
[3] Goodfellow, I. et al. (2014). Generative Adversarial Nets. NeurIPS 2014.
[4] Mao, X. et al. (2017). Least Squares Generative Adversarial Networks. CVPR 2017.
[5] Johnson, J., Alahi, A., & Fei-Fei, L. (2016). Perceptual Losses for Real-Time Style Transfer and Super-Resolution. ECCV 2016.
[6] Shrivastava, A. et al. (2017). Learning from Simulated and Unsupervised Images through Adversarial Training. CVPR 2017.
[7] Ulyanov, D., Vedaldi, A., & Lempitsky, V. (2016). Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv:1607.08022.
Repo Link:
Codes for the project can be found here
Mentors & Mentees Details
Mentors:
- Aryan Palimkar [Compsoc] : 241CS112
- Pradyun D [Compsoc] : 241CS141
- Vivek Kashyap [Compsoc] : 241AI043
Mentees:
- Amoolya Kamath: 251CS106
- Swaraj Shinde: 251CS262
- Kabir Sethi: 251DS013
- Soma Svanik: 251IT073
Report Information
Report Details
Created: May 17, 2026, 11:14 p.m.
Approved by: None
Approval date: None
Report Details
Created: May 17, 2026, 11:14 p.m.
Approved by: None
Approval date: None