

D09 - MAC-Forge: Systolic Array Based AI Accelerator
Abstract
Abstract
MAC-Forge: Architecting the Silicon Behind AI
Project Details
- GitHub Repository: advaitkuvalekarnitk/MACForge
- Google Meet Link: https://meet.google.com/sou-smpf-rkf
- Video Demonstration: MACForge.mov - Google Drive
- Mentees: Advait Aniket Kuvalekar, Shobhit Butola, G Hemesh Rao Pole, Sanath, Aditya Bhagat, Sai Sharan SK, Pranay Saha
- Mentors: Chetan S K, Shamit Hoysal, Shridhar Bhat
Aim
- Design a systolic array architecture for efficient parallel matrix multiplication or multiply-accumulate operations.
- Implement the design using synthesizable Verilog for hardware realization.
- Arrange processing elements in a pipelined, rhythmic data flow to maximize throughput.
- Understand hardware-level parallelism and dataflow in systolic array structures.
Introduction
This project implements a “Tiny TPU” matrix accelerator using Verilog HDL, based on the systolic array architecture commonly used in industry-leading AI chips such as Google’s TPU and NVIDIA’s Tensor Cores.
In an era where silicon limits performance more than software, and general-purpose CPUs fall short for deep learning workloads, this project offers a hands-on opportunity to explore domain-specific hardware acceleration. By designing the TinyTPU, mentees gain a deep understanding of parallel computation and the building blocks of high-performance AI hardware.
Technologies Used
- Verilog HDL – Hardware design
- Xilinx Vivado – Design, synthesis, simulation, and implementation
- Python & HTML – Building a visualization dashboard from simulation data (
.csvfile)
Design Methodology
Phase 1: RTL Hardware Architecture Design
- Processing Element (PE) Design:
- Module:
proc_element_ws.sv - Acts as a dedicated Multiply-Accumulate (MAC) unit.
- Stores a 32-bit stationary weight.
- Each cycle: multiplies incoming activation × weight, adds partial sum, routes results downward, and passes activation right.
- Module:
- Grid Instantiation & Routing:
- Module:
systolic_array_ws.sv - Verilog
generateblocks used to wire 16 PEs into a 4×4 matrix. - Managed boundary conditions (padding edge inputs with zeros).
- Module:
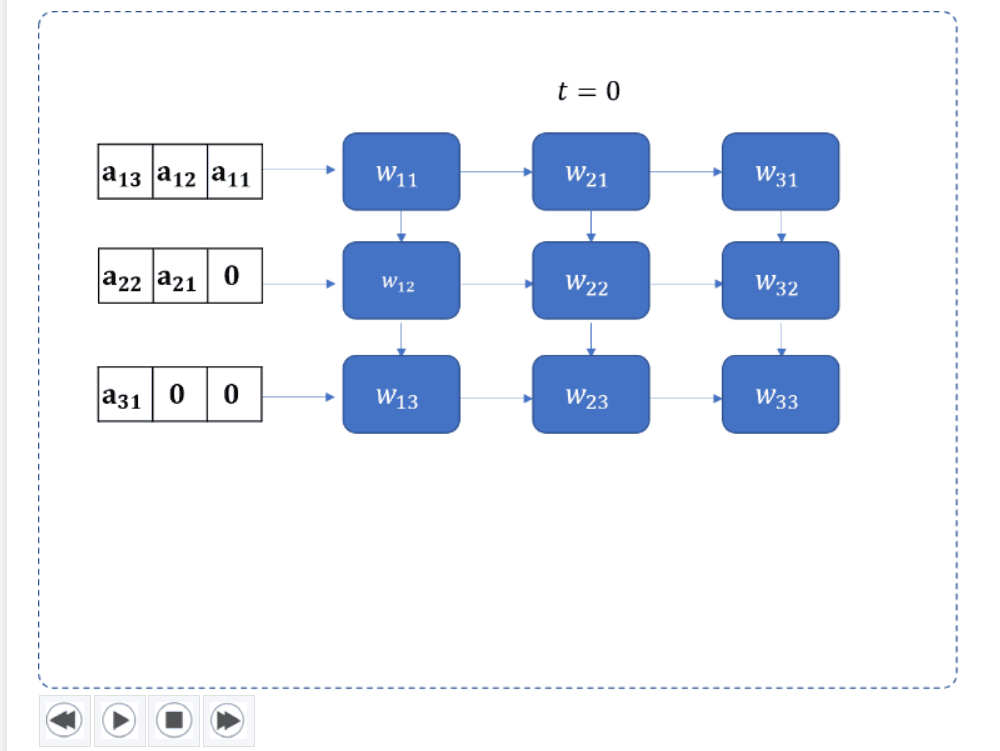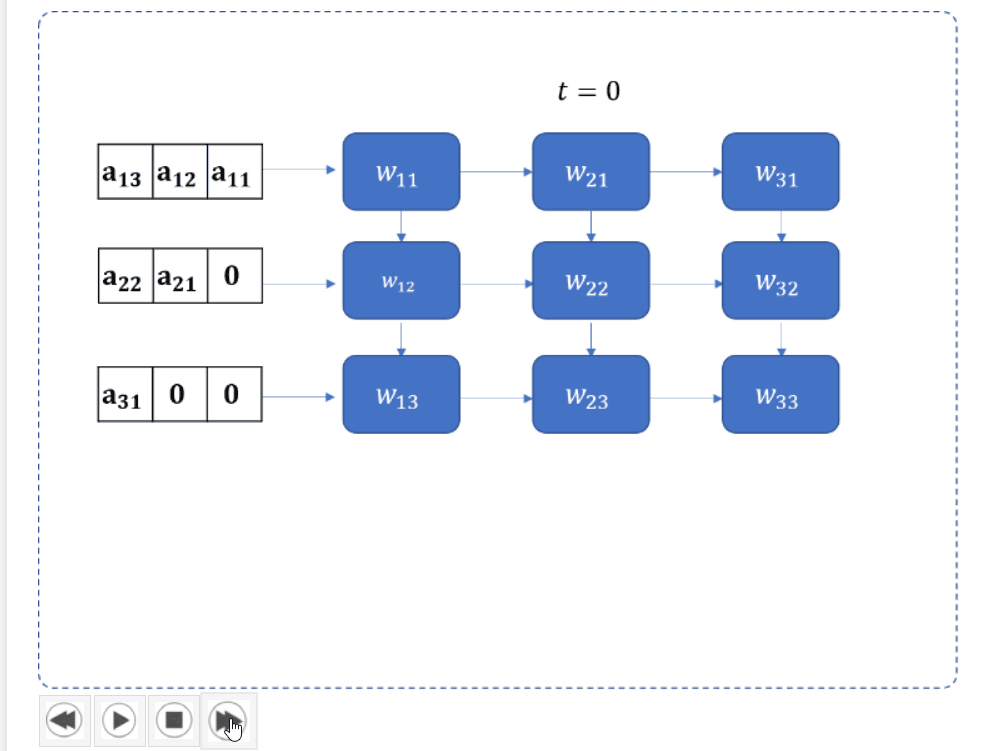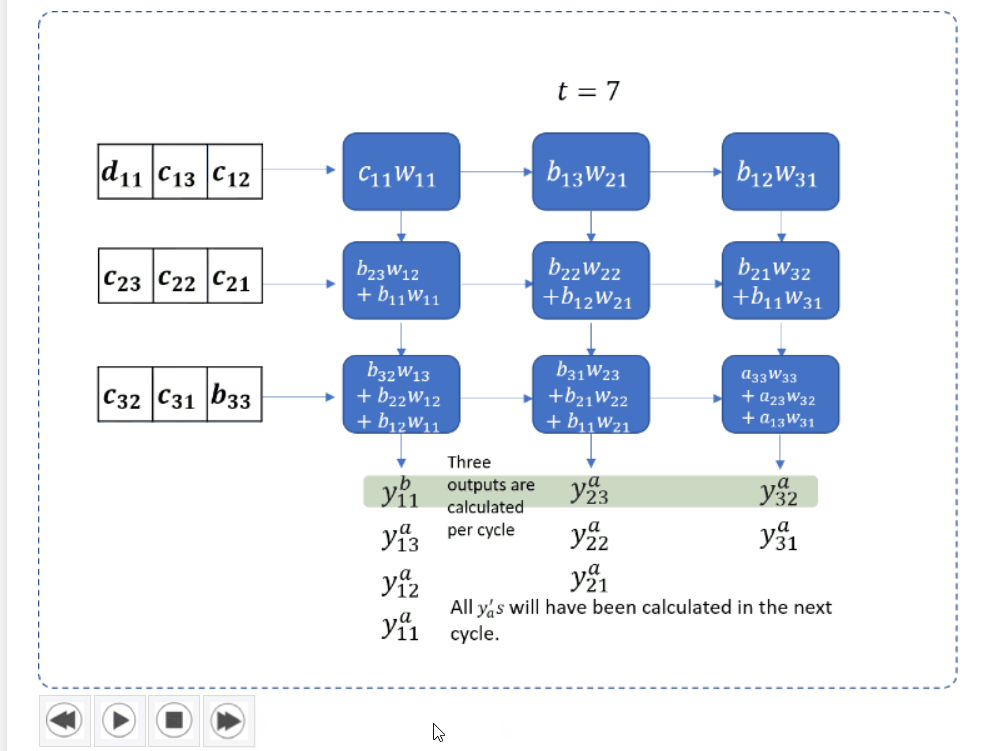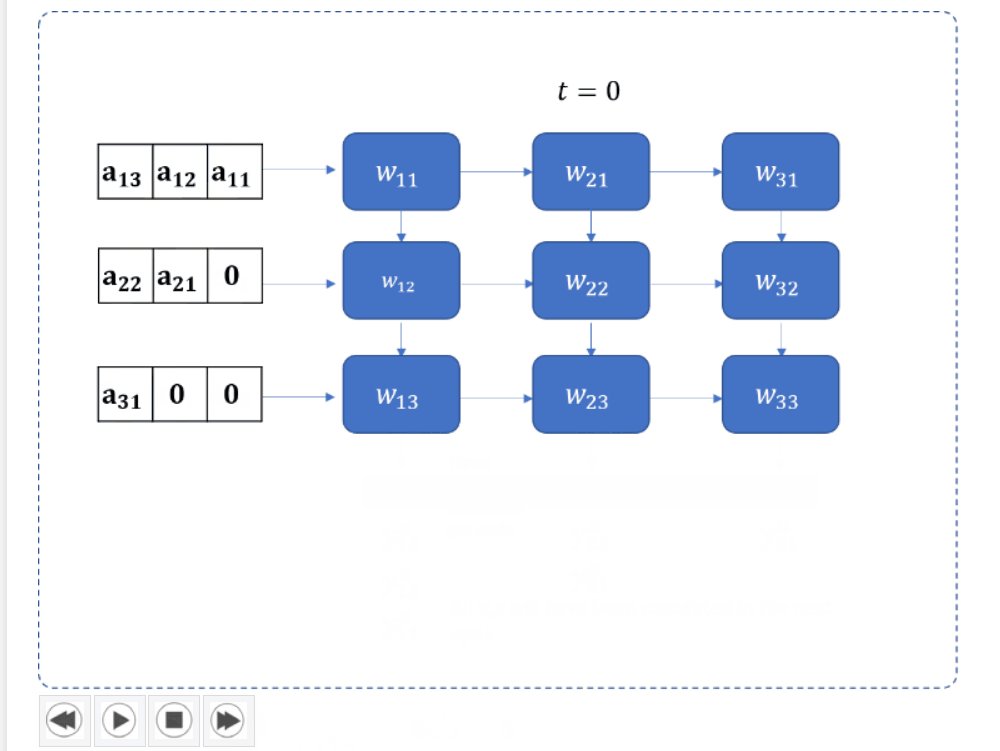
Phase 2: Automated Testbench & State Extraction
- Testbench:
systolic_array_ws_tb.sv - Test Vector Generation: Randomized 32-bit signed integers, identity matrices, and negative arrays.
- Cycle-by-Cycle CSV Logging:
$fopenand$fwriteused to log 64-bit register states of all 16 PEs.- Output stored in
sim_data.csvfor permanent, parseable records.
Phase 3: Software Dashboard & UI Generation
- Python Tool:
build_dashboard.py - Data Parsing: Filters uninitialized states, organizes hardware data by test scenarios.
- Dynamic HTML Rendering:
- Generates a standalone HTML/JS dashboard.
- 4×4 grid UI with forward/backward stepping through cycles.
- Visualizes the diagonal population of the grid, validating 3N–1 cycle latency.
Simulation Conditions
- Environment: Xilinx Vivado 2025.2
- Software: Python 3.10+, HTML5/CSS3/JavaScript
- Clock Period: 10 ns (100 MHz theoretical)
- Datapath: 32-bit signed inputs, 64-bit accumulators
- Grid Dimensions: 4×4 (N=4)
Results
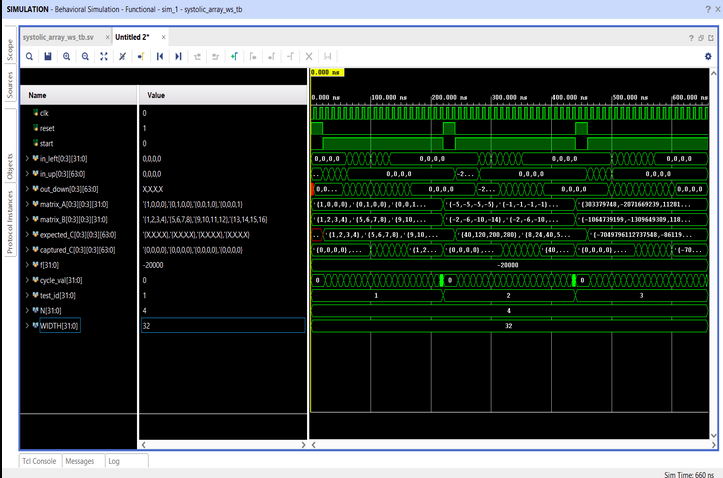
Hardware Verification (Waveform Analysis)
- Correct propagation delays verified.
- 32-bit signed numbers cascaded successfully.
- MAC results matched software model outputs.
- Zero mismatches found.
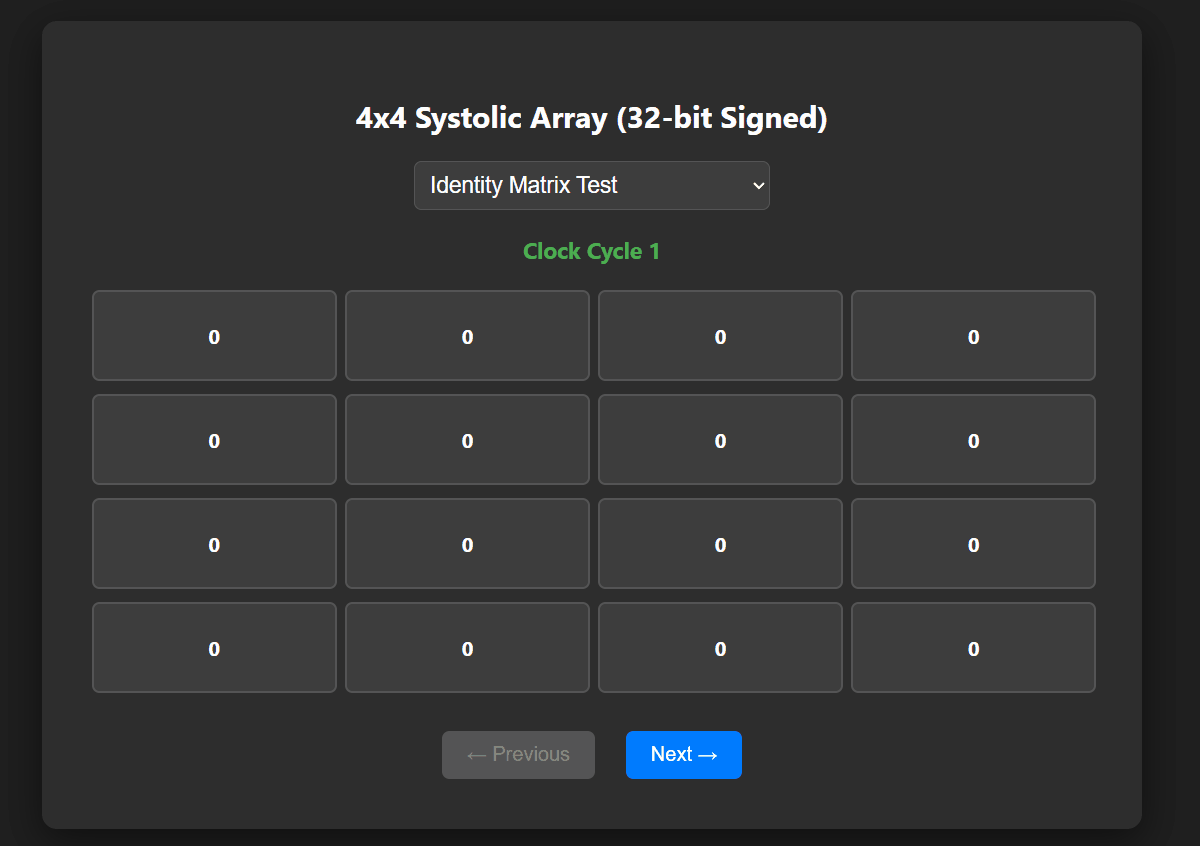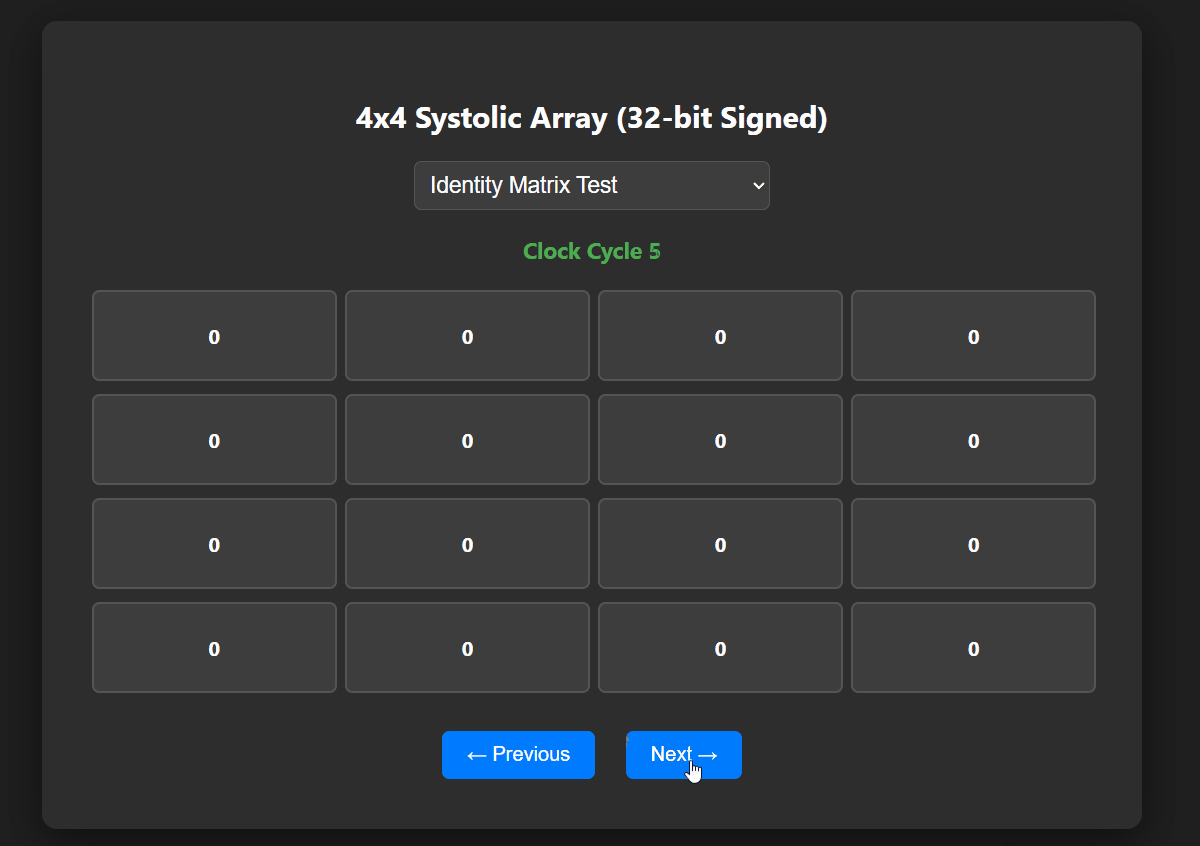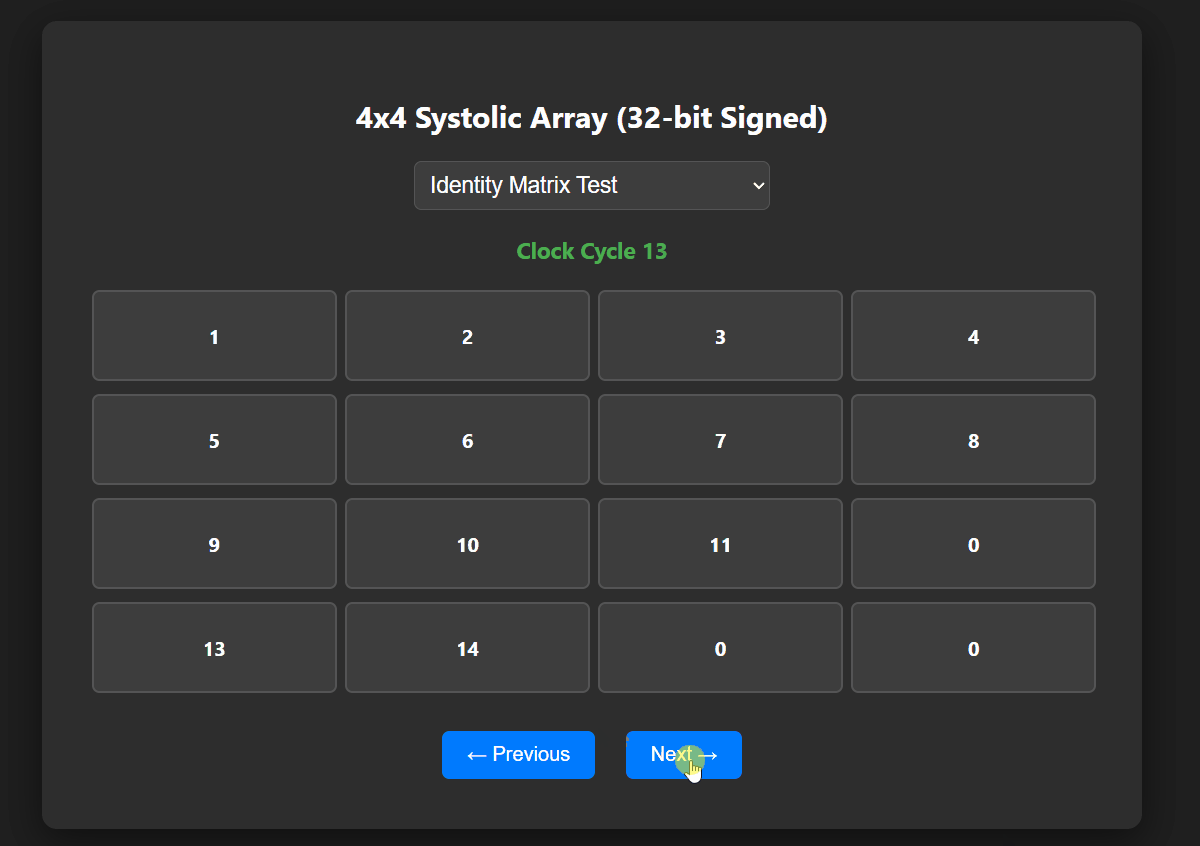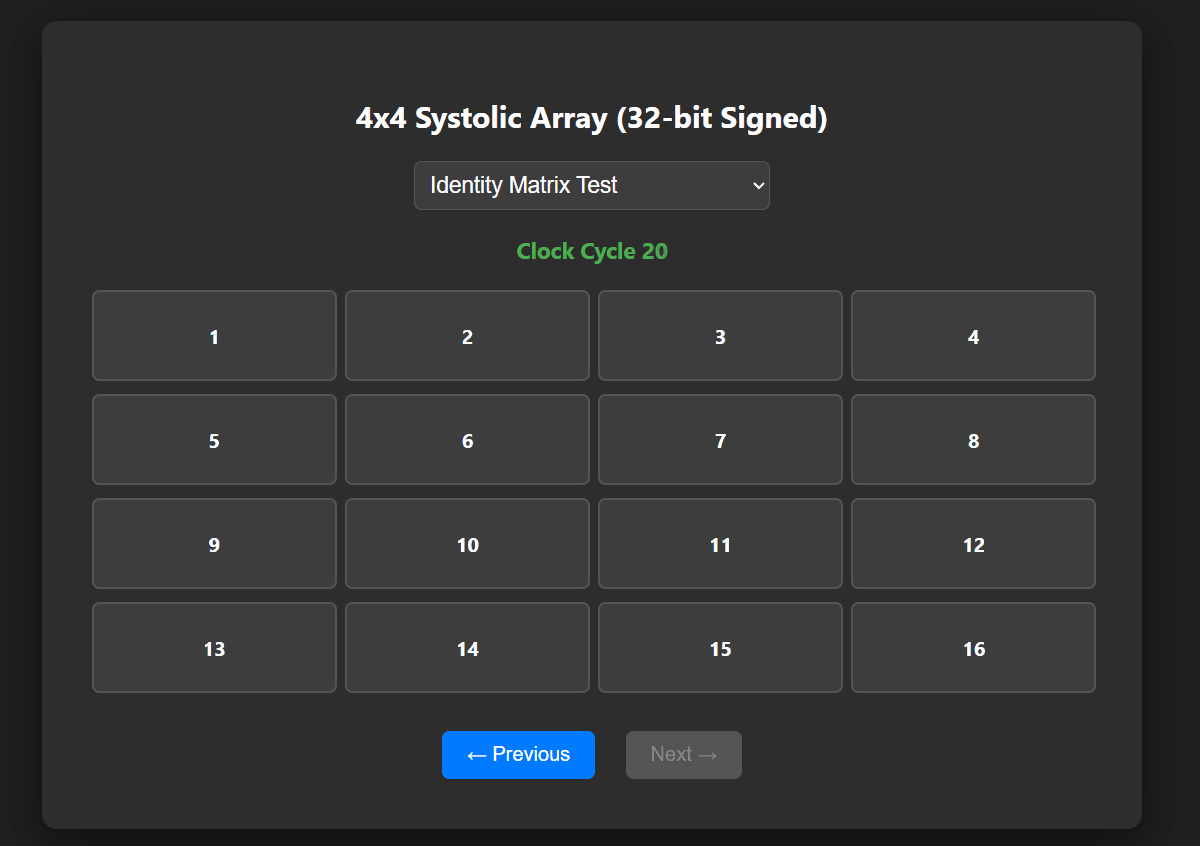
Software Verification (Visual Dashboard)
- Python script parsed hardware data correctly.
- Interactive UI validated diagonal grid data flow.
- Confirmed exact cycle latency requirements.
Conclusion
The project successfully designed and verified a 4×4 Weight-Stationary Systolic Array. By extracting hardware states into a custom software dashboard, it bridges low-level RTL debugging with high-level algorithmic visualization. Results validate the principles of high arithmetic intensity and demonstrate how systolic architectures mitigate memory bottlenecks while executing complex 32-bit signed matrix multiplication.
Future Scope
- FPGA Synthesis: Timing closure and area utilization analysis.
- AXI4-Stream Integration: Interface with ARM processor memory subsystem via DMA.
- Scalability: Expand N=4 to larger grids, analyze routing and utilization impacts.
References
- A. Ankur, “Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture,” Telesens, Jul. 30, 2018.
- Tensor Processing Unit (YouTube Video)
- C. Shinn, Tiny TPU Project Repository
- Debtanu09, Systolic Array Matrix Multiplier Repository
- H. T. Kung, “Why systolic architectures?,” Computer, vol. 15, no. 1, pp. 37–46, Jan. 1982.
Report Information
Team Members
Team Members
Report Details
Created: May 17, 2026, 1:47 p.m.
Approved by: None
Approval date: None
Report Details
Created: May 17, 2026, 1:47 p.m.
Approved by: None
Approval date: None