

STreaM32
Abstract
Abstract
Aim
The project aims to solve the challenge of deploying real-time video compression on highly resource-constrained embedded systems.
The core problems include:
- Deploying machine learning models on microcontrollers with limited memory and compute capacity
- Designing a compact and efficient video encoder using lightweight neural architectures (e.g., autoencoders/CNNs)
- Achieving real-time frame acquisition, compression, and transmission under strict latency constraints
- Enabling reliable wireless streaming over low-bandwidth communication channels
- Developing a decoder capable of reconstructing compressed frames in real time on a host machine
Methodology
The system is implemented as a pipeline consisting of model design, embedded deployment, and system integration.
Model Design
A lightweight autoencoder-based architecture is used for video compression. The encoder compresses input frames into a compact latent representation. The model is trained offline using standard deep learning frameworks. Post-training, the model is quantized (e.g., INT8) using TensorFlow Lite to reduce memory and computation requirements
Embedded Deployment
The quantized encoder model is deployed on an STM32N6 board. Input frames are captured via a camera module interfaced with the MCU. Each frame is processed in real time through the encoder.
Optimization techniques include:
- Fixed-point arithmetic
- Memory reuse
- Layer-wise optimization for inference speed
Communication Pipeline
Compressed data is transmitted wirelessly using Serial. Data framing and synchronization mechanisms are implemented to ensure reliable streaming. Bandwidth constraints are handled through aggressive compression
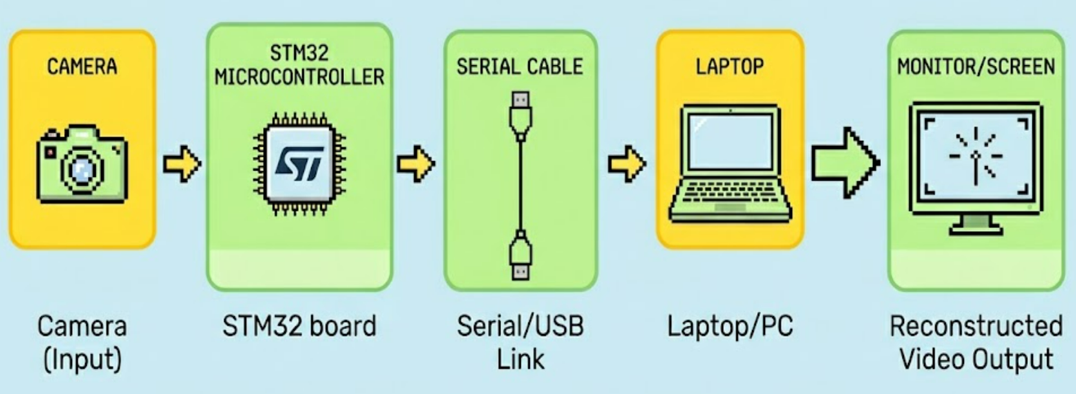
Decoder Implementation
A Python-based decoder runs on a host system. It receives compressed latent representations. The decoder reconstructs frames using the corresponding neural network decoder. Real-time display is achieved using efficient buffering and rendering.
Model Architecture
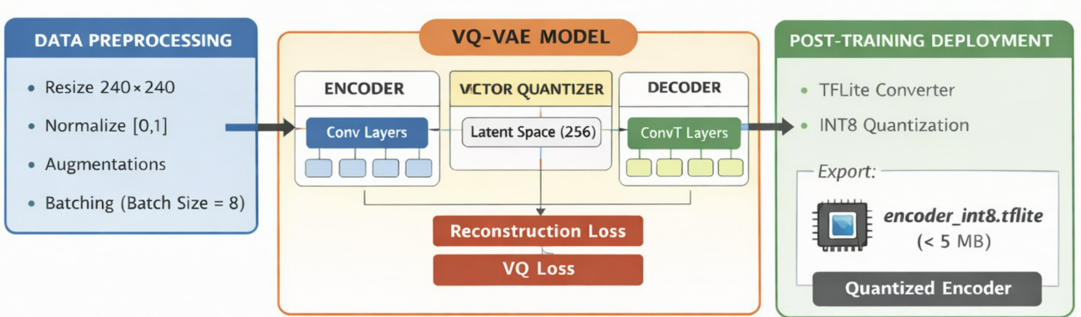
Results

Conclusion
Viability on Edge Devices:deep-learning-based compression is a strong alternative for resource-constrained hardware.
Scalable Blueprint: Established a foundation for deploying high-quality, low-latency video streaming on the STM32.
Future Work
- Hybrid Architecture: Combine Method 1’s residual logic with Method 2’s codebook to encode only the changes in discrete indices for maximum compression.
- Perceptual Optimization: Replace standard MSE loss with SSIM based or adversarial loss to improve visual sharpness and reduce blur at low bitrates
- Transfer data wirelessly using ESP WiFi module
Mentees:
Varun Uthej Reddy
Hardhik Thiriveedi
Joseph
Mentors:
Asrith Singampalli
Guhan Balaji
Dammu Chaitanya
Report Information
Team Members
Team Members
Report Details
Created: April 7, 2026, 8:16 p.m.
Approved by: None
Approval date: None
Report Details
Created: April 7, 2026, 8:16 p.m.
Approved by: None
Approval date: None